

「画像生成AIを使ってみたいけど、Stable Diffusionって難しそう…」
「無料で使えるって本当?どこから始めればいいの?」
そんな風に思っていませんか?
実は、Stable DiffusionはAI画像生成の世界を切り開いたパイオニア的存在。
しかも、オープンソースだから基本無料で使えて、商用利用もOKなんです。
この記事では、Stable Diffusionの基本から実践的な使い方、料金プラン、そしてあなたに合った始め方まで、すべてを分かりやすく解説します。
AI画像生成はここから始まったと言っても過言ではありません。
一緒に、その世界への第一歩を踏み出しましょう。
Stable Diffusionとは
Stable Diffusionは、イギリスのStability AI社が2022年に公開したオープンソースの画像生成AIです。

テキストで「こんな画像がほしい」と伝えるだけで、AIがその場で画像を作り出してくれます。
たとえば「夕日に照らされた海辺のカフェ」と入力すれば、そのイメージに合った画像が数秒〜数十秒で生成されるんです。
Stable Diffusionの最大の特徴は、誰でも無料で使えるオープンソースであること。
MidjourneyやDALL-Eといった有名な画像生成AIは基本的に有料ですが、Stable Diffusionは自分のパソコンにインストールすれば完全無料で利用できます。
技術的には「拡散モデル(Diffusion Model)」という仕組みを採用しています。
これは、ノイズだらけの画像から少しずつノイズを取り除いていくことで、最終的にきれいな画像を作り出す方法です。
想像してみてください。
砂嵐のようなザラザラの画面から、だんだんと絵が浮かび上がってくるような感じです。
2024年10月には最新版「Stable Diffusion 3.5」がリリースされ、画質・プロンプトの理解力・多様性がさらに向上しました。
8.1億パラメータを持つ「Stable Diffusion 3.5 Large」は、プロ品質の画像を1メガピクセル解像度で生成できるようになっています。
Stable Diffusionでできること
Stable Diffusionは、単に「画像を作る」だけではありません。
実はかなり多機能で、使いこなせば創作の幅が一気に広がります。
ここでは、Stable Diffusionでできることを機能別に紹介していきますね。

基本的な画像生成
- 🎨 テキストから画像を生成(txt2img):文字で指示を出すだけで、AIがゼロから画像を作成します。「赤いドレスを着た女性のポートレート」のように具体的に書くほど、イメージ通りの画像が生まれます。
- 🔄 画像から画像を生成(img2img):既存の画像をベースに、新しい画像を生成できます。ラフスケッチを清書したり、写真をイラスト風に変換したりと、アイデア次第で使い方は無限大です。
- 🖼️ アスペクト比の自由な設定:正方形、縦長、横長など、用途に合わせた縦横比で画像を生成できます。SNS用、ブログ用、ポスター用など、目的に応じた最適なサイズで作れます。
- 🎲 シード値による再現性の確保:同じシード値を使えば、同じ画像を何度でも再現可能。気に入った画像のバリエーションを作りたいときに便利です。
画像の編集・修正
- 🩹 インペインティング(Inpainting):画像の一部だけをマスクで指定して、その部分だけを再生成できます。「この部分だけ変えたい」という細かい修正が可能です。
- 🖼️ アウトペインティング(Outpainting):画像の外側に新しい要素を描き足せます。構図を広げたい、見切れた部分を補完したいときに活躍します。
- 🚫 不要なオブジェクトの削除(Erase Object):写真に写り込んだ邪魔な物体を自然に消去できます。背景に溶け込むように処理されるので、まるで最初からなかったかのよう。
- 🔍 検索と置換(Search and Replace):画像内の特定のオブジェクトを、別のものに自動で置き換えられます。「りんごをオレンジに変えて」のような指示が可能です。
- 🎨 検索とリカラー(Search and Recolor):特定のオブジェクトの色だけを変更できます。「車を青から赤に」といった色の変更が簡単にできます。
- ✂️ 背景の削除(Remove Background):被写体だけを残して背景を透過処理できます。商品画像の切り抜きや、合成素材の作成に重宝します。
- 🌅 背景の置換とリライト(Replace Background & Relight):背景を別の画像に差し替え、照明も自動調整してくれます。被写体と背景が自然に馴染むように処理されます。
画像の品質向上
- 📈 高解像度化(Hires.fix):低解像度で生成した画像を、高解像度に引き上げながら細部を再描画します。生成時間を短縮しつつ、最終的には高品質な画像が得られます。
- 🔬 クリエイティブアップスケーラー:低解像度の画像を4Kまでアップスケールしながら、プロンプトで追加の指示も出せます。単なる拡大ではなく、AIが細部を補完してくれます。
- 🖥️ コンサバティブアップスケーラー:元の画像を忠実に保ちながら4Kまで解像度を上げます。画像の雰囲気を変えたくないときに最適です。
- ⚡ ファストアップスケーラー:低コストで手軽に解像度を上げたいときに。4メガピクセルまで拡大できます。
構図・ポーズのコントロール
- 🎯 ControlNet:画像生成時のポーズや構図を細かくコントロールできる拡張機能です。参照画像の骨格や輪郭線を抽出して、その構図を維持したまま新しい画像を生成できます。
- 🦴 OpenPose:人体のポーズを棒人間のように検出し、そのポーズを再現した画像を生成します。特定のポーズのキャラクターを描きたいときに便利です。
- ✏️ Canny(輪郭検出):画像の輪郭線を抽出して、その線画をベースに新しい画像を生成できます。ラフスケッチからの清書に向いています。
- 🏗️ Structure(構造):入力画像の構造を維持しながら、新しいスタイルで画像を生成します。建物の写真を維持しつつアート風にするなど。
- ✍️ Sketch(スケッチ):手描きのスケッチやライン画を元に、本格的な画像を生成できます。絵が苦手な人でも、ラフな線画さえ描ければOKです。
- 🎨 Style Guide(スタイルガイド):参照画像のスタイルを抽出し、そのテイストで新しい画像を生成します。
- 🖌️ Style Transfer(スタイルトランスファー):ある画像のビジュアルスタイルを別の画像に適用できます。複数のコンテンツで一貫したスタイルを維持したいときに。
モデルのカスタマイズ
- 📦 Checkpointモデルの切り替え:アニメ調、実写風、イラスト調など、目的に応じたモデルを選んで使い分けられます。モデルによって画風が大きく変わります。
- 🎀 LoRA(Low-Rank Adaptation):特定のキャラクターやスタイルを小さなファイルで追加学習できます。Checkpointモデルに「トッピング」を加えるようなイメージです。
- 📝 Textual Inversion(Embeddings):特定のコンセプトを短いキーワードに凝縮して学習させる手法。少ない画像でも独自の概念を覚えさせられます。
- 🔗 Hypernetwork:モデルの出力に追加レイヤーを加える微調整手法です。スタイルの微妙なニュアンスを調整したいときに使われます。
- 🎨 VAE(Variational Autoencoder):画像の色味や鮮やかさを調整するコンポーネント。VAEを変更することで、同じモデルでも色彩表現が変わります。
プロンプトによる詳細な制御
- ✨ ポジティブプロンプト:生成したい画像の要素を指定します。描いてほしいものを具体的に伝えましょう。
- 🚫 ネガティブプロンプト:生成したくない要素を指定します。「低品質」「ぼやけた」など、避けたい特徴を除外できます。
- ⚖️ CFG Scale(プロンプト忠実度):プロンプトにどれだけ忠実に従うかを数値で調整できます。高いほど指示に忠実、低いほどAIの自由度が上がります。
- 🔢 重み付け:特定のキーワードを強調したり弱めたりできます。括弧で囲んで(keyword:1.5)のように指定します。
- ⏸️ BREAK構文:プロンプトを区切って、要素ごとの影響範囲を明確にできます。複雑な指示を整理するのに便利です。
その他の便利機能
- 🎬 動画生成(Stable Video Diffusion):静止画から数秒の動画を生成できます。画像に命を吹き込みたいときに。
- 🔊 音声生成(Stable Audio):テキストから最大3分の高品質な音声を生成できます。BGMや効果音の作成に活用できます。
- 🧊 3D生成(Stable Fast 3D):2D画像から3Dモデルを生成できます。ゲームやARコンテンツの素材作りに。
- 🧩 拡張機能のサポート:コミュニティが作った様々な拡張機能を追加できます。機能を自由に拡張していける柔軟性があります。
Stable Diffusionの使い方ガイド
Stable Diffusionの使い方は、大きく分けて3つあります。
あなたの環境や目的に合った方法を選んでみてください。
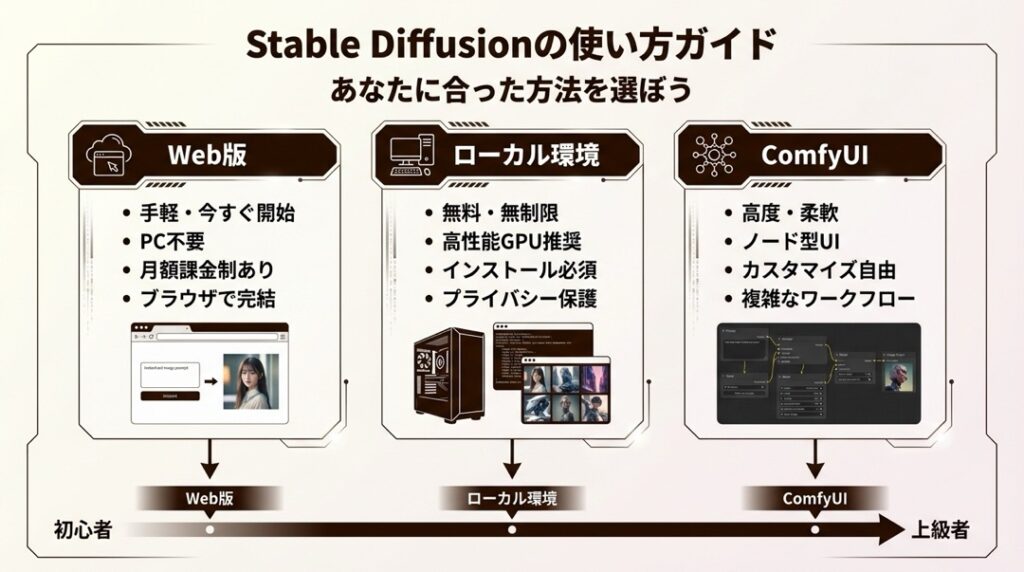
Web版で手軽に始める
最も手軽なのは、ブラウザから使えるWeb版です。
インストール不要で、今すぐ試せます。
DreamStudioは、Stability AI公式のWebアプリです。
最新のStable Diffusionモデルを使えて、操作も直感的。
新規登録で25クレジット(約25枚分)が無料でもらえます。
使い方は簡単です。
- DreamStudio(dreamstudio.ai)にアクセス
- アカウントを作成してログイン
- プロンプト欄に英語で指示を入力
- 「Generate」ボタンをクリック
15秒ほど待てば、画像が生成されます。
Hugging Faceでも無料でStable Diffusionを試せます。
Stable Diffusion 2.1のデモなどが公開されていて、アカウントなしでも使えます。
ただし、DreamStudioより生成に時間がかかることがあります。
ローカル環境で本格的に使う
より自由度高く、無制限に使いたいなら、自分のPCにインストールするのがおすすめです。
一度環境を構築すれば、何枚生成しても完全無料です。
ただし、GPUが必要です。
最低でもVRAM 6GB以上、できれば8GB以上のNVIDIA製グラフィックボードが推奨されます。
Stable Diffusion Web UI(AUTOMATIC1111版)が、最も人気のある選択肢です。
# インストール手順
1. Python 3.10.6をインストール
2. Gitをインストール
3. 以下のコマンドでWeb UIをクローン
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
4. Hugging Faceからモデルをダウンロードしてmodelsフォルダに配置
5. webui-user.batを実行
6. ブラウザで http://127.0.0.1:7860 にアクセス最初のセットアップには10分ほどかかりますが、一度構築すれば快適に使えます。
Forge版も人気が高まっています。
AUTOMATIC1111版をベースに最適化されていて、より低いVRAMでも動作します。
Stable Diffusion 3.5 Mediumは、わずか9.9GBのVRAMで動作可能です。
ComfyUIでノードベースの操作
より高度なワークフローを組みたい上級者には、ComfyUIがおすすめです。
ノード(箱)をつないで画像生成のパイプラインを視覚的に構築できます。
複雑な処理も、一度ワークフローを作れば繰り返し実行できます。
Stable Diffusionの内部処理を理解するのにも最適なツールです。
はじめての画像生成
環境が整ったら、実際に画像を生成してみましょう。
# 基本的なプロンプトの書き方
プロンプト(ポジティブ):
1girl, beautiful, long hair, blue eyes, standing, outdoor, sunlight
ネガティブプロンプト:
low quality, blurry, bad anatomy, worst qualityプロンプトのコツは、具体的に書くこと。
「女の子」より「1girl, beautiful, long black hair, blue eyes, smiling」のように、細かく指定すると理想に近づきます。
パラメータの目安は以下の通りです。
サンプリングステップ数は20〜30程度、CFG Scaleは7前後がバランスの良い設定です。
サンプラーは「DPM++ 2M Karras」や「Euler a」がおすすめです。
Stable Diffusionの料金プラン
Stable Diffusionは、使い方によって料金体系が異なります。
自分に合ったプランを選びましょう。

完全無料:ローカル環境
自分のPCにインストールして使う場合、Stable Diffusionの利用料金は0円です。
オープンソースなので、モデルのダウンロードも、画像生成も、何回使っても無料。
ただし、PCのスペック(特にGPU)と電気代は自己負担になります。
必要なGPUスペックの目安として、VRAM 6GB以上のNVIDIA製グラフィックボードがあれば動作します。
快適に使いたいなら8GB以上、最新モデルをフル活用するなら12GB以上が理想です。
クレジット制:Stability AI API / DreamStudio
Stability AIの公式サービスを使う場合は、クレジット制になります。
1クレジット = 0.01ドル(約1.5円)
新規登録で25クレジットが無料でもらえます。
追加購入は10ドルで1,000クレジットから。
APIの料金例は以下の通りです。
画像生成(SD3.5 Large)は1枚あたり6.5クレジット(約10円)、クリエイティブアップスケーラー(4K化)は60クレジット(約90円)、インペインティングやアウトペインティングは4〜5クレジット程度です。
DreamStudioでは、デフォルト設定で1クレジットあたり約5枚生成できます。
設定(解像度やステップ数)を上げると消費クレジットも増えます。
商用ライセンス:Stability AI Community License
Stable Diffusionを商用利用する場合のライセンスは、売上規模によって異なります。
非商用利用(研究含む):無料
年間売上100万ドル未満の商用利用:無料
年間売上100万ドル以上の商用利用:Enterprise Licenseが必要(要問い合わせ)
つまり、多くの個人クリエイターや中小企業は無料で商用利用可能です。
生成した画像の著作権もユーザーに帰属するので、安心して使えます。
Stable Diffusionはどんな人におすすめ?
Stable Diffusionは幅広い用途に対応しますが、特に以下のような人に向いています。

コストを抑えて画像生成AIを使いたい人
MidjourneyやDALL-Eは月額課金が基本ですが、Stable Diffusionはローカル環境なら完全無料。
「とりあえず試してみたい」「大量に生成したい」という人にぴったりです。
初期投資としてGPUが必要ですが、すでにゲーミングPCを持っている人なら追加費用ゼロで始められます。
カスタマイズ性を重視するクリエイター
オープンソースの強みは、自由度の高さです。
Checkpointモデル、LoRA、ControlNetなど、無数のカスタマイズ手段が用意されています。
「特定のアニメ調」「リアルな実写風」「独自のキャラクター」など、他のAIでは難しい細かい調整が可能です。
プログラミングや技術に興味がある人
Stable Diffusionを深く使いこなすと、AIの仕組みへの理解が自然と深まります。
ComfyUIでワークフローを組んだり、LoRAを学習させたりすることで、AI技術のスキルアップにもつながります。
将来的にAI関連の仕事を考えている人にとって、良い学習教材にもなります。
商用利用を視野に入れている人
Stable Diffusionは、年間売上100万ドル未満なら商用利用も無料。
生成画像の権利もユーザーに帰属するので、ビジネスに活用しやすいです。
ただし、使用するモデルによっては商用利用不可の場合もあります。
Civitaiなどのモデル配布サイトでダウンロードする際は、ライセンス表記を必ず確認しましょう。
Stable DiffusionのFAQ
Stable Diffusionは本当に無料で使えますか?
はい、Stable Diffusionはオープンソースなので、自分のPCにインストールすれば完全無料で使えます。
Web版のDreamStudioやAPIを使う場合は、一定量を超えると有料になります。
ただし、新規登録で25クレジット(約25枚分)は無料でもらえます。
Stable Diffusionを動かすのに必要なPCスペックは?
VRAM 6GB以上のNVIDIA製GPUが最低条件です。
快適に使うならVRAM 8GB以上、最新のStable Diffusion 3.5を使うならVRAM 10GB以上が推奨です。
CPUやRAMも重要ですが、画像生成速度はGPUの性能で大きく変わります。
NVIDIA RTX 3060(12GB)やRTX 4060あたりが、コスパの良い選択肢です。
Stable Diffusionで生成した画像は商用利用できますか?
基本的には商用利用可能です。
Stability AIのCommunity Licenseでは、年間売上100万ドル未満の組織は無料で商用利用できます。
生成した画像の著作権もユーザーに帰属します。
ただし注意点があります。
使用するモデル(特にCivitaiなどからダウンロードしたもの)によっては、商用利用が禁止されている場合があります。
また、既存のキャラクターや著作物に似た画像を生成した場合、著作権侵害のリスクがあります。
Stable DiffusionとMidjourney、どちらがおすすめですか?
用途によって異なります。
Stable Diffusionが向いている人:無料で使いたい、細かくカスタマイズしたい、ローカルで動かしたい、技術的な学びを得たい
Midjourneyが向いている人:手軽に高品質な画像がほしい、環境構築が面倒、Discordでサクッと使いたい
Stable Diffusionは自由度が高い分、学習コストもかかります。
「まずは試したい」ならMidjourneyやDreamStudio、「本格的に取り組みたい」ならStable Diffusionのローカル環境がおすすめです。
Stable Diffusionで日本語のプロンプトは使えますか?
基本的に英語でのプロンプトが推奨されます。
Stable Diffusionは英語のテキストで学習されているため、日本語を入力しても意図した結果が得られないことが多いです。
「beautiful girl」を「美しい女の子」と入力しても、うまく認識されません。
英語が苦手な場合は、翻訳ツールを使ってプロンプトを作成するか、日本語対応のモデルを探してみてください。
Stable Diffusionであなたの創造力を解放しよう
ここまで、Stable Diffusionの基本から使い方、料金プランまで解説してきました。
AI画像生成の世界は、Stable Diffusionから始まりました。
そして今、あなたもその世界に足を踏み入れようとしています。
最初は操作に戸惑うこともあるかもしれません。
でも大丈夫です。
一歩ずつ進んでいけば、きっと「こんな画像が作れるなんて!」という感動が待っています。
想像を形にする力。
それがStable Diffusionです。
あなたの創造力を、今日から解放してみませんか?

